【MXGS-577】人妻女雀士 ~AV初出演ドキュメント~ 雪菜</a>2013-11-16マキシング&$MAXING118分钟 中科大/华为诺亚开首!芯片性能≠布局评分,EDA联想框架全面开源

ChipBench团队 投稿【MXGS-577】人妻女雀士 ~AV初出演ドキュメント~ 雪菜2013-11-16マキシング&$MAXING118分钟
量子位 | 公众号 QbitAI
伦理小说网芯片物理布局,有了直指性能成见的新测评圭表!
中科大MIRA Lab和华为诺亚方舟实践室斡旋发布了新的评估框架和数据集,况兼十足开源。
有了这套圭表,布局成见与最终的端到端性能不一致、得分高而PPA性能却偏低的问题,就有望得到处罚了。

在芯片联想当中,电子联想自动化(EDA)是至关伏击的一环,在业界被称为“芯片之母”,而芯片物理布局(Placement)又是其中的要害要道。
芯片物理布局问题是一个NP-hard问题,东说念主们尝试着通过AI来进行这项职责,但费事一个灵验的评测圭表。
传统的评估圭臬——代理成见诚然易于盘算,但频频与芯片最终的端到端性能存在权贵各异。
为了弥补这一领域,中科大MIRA Lab和华为诺亚方舟实践室斡旋发布了这个名为ChiPBench的评估框架,以及有关数据集。
跟着ChiPBench的上线,作家也发现了刻下芯片布局算法存在许多不及,教导有关商量东说念主员是时间研发新算法了。
芯片联想经由靠近挑战笔据“摩尔定律”,集成电路(IC)的范围发生了指数级增长,对芯片联想带来了前所未有的挑战。
为了搪塞这种日益增长的复杂性,EDA器具应时而生,为硬件工程师提供了极大的匡助。
EDA器具大概自动完成芯片联想职责经由中的各个要道,包括高级次抽象、逻辑抽象、物理联想、测试和考证等要道。
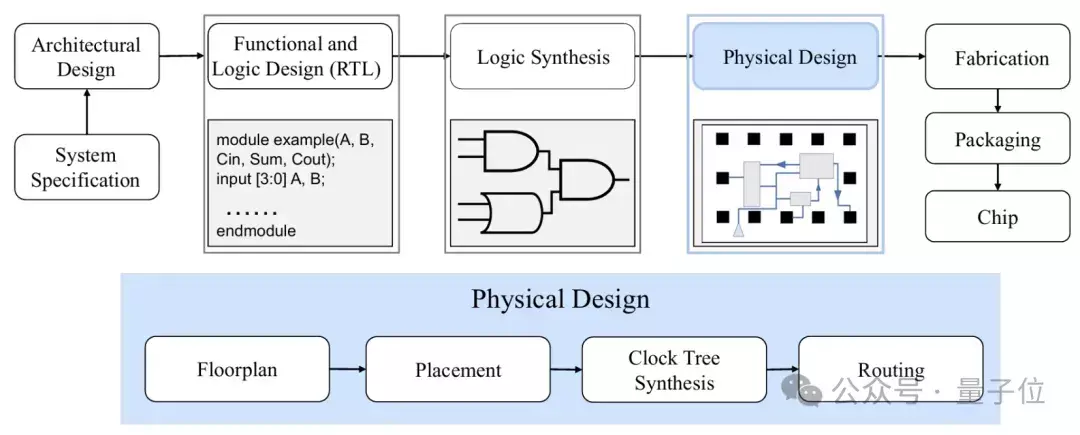
其中,芯片布局是一个伏击要道,该阶段又不错分为两个子阶段——宏布局缓和序单位布局。
宏布局是超大范围集成(VLSI)物理联想中的一个要害问题,主要波及较大元件(如SRAM和时钟发生器,正常称为宏)的摆设。
这一阶段对芯片的举座布局以及线长、功耗和面积等伏击联想参数具有权贵影响。
之后的圭表单位布局阶段,需要处理的是数目更多、体积更小的圭表单位的摆设问题,这些单位是数字联想的基本构成部分。
正常,该阶段诳骗组合优化求解等花样来完竣布局摆放的优化,最猛进程地减少单位间的距离,为后续的布线职责奠定邃密的基础,并在一定进程上优化互联时序性能。
芯片布局传统上由东说念主类专科联想师手工完成,这不仅恣虐多数东说念主力,况兼需要多数的各人先验常识。
因此,许多联想自动化花样,尤其是基于东说念主工智能的算法,被开荒出来以完竣这一过程的自动化。
然则,由于芯片联想的职责经由较长,对这些算法的评估正常斡旋在易于盘算的中间代理成见上(举例半周长线长HPWL,布局单位密度等),但这些成见时常与端到端性能(即最终联想的 PPA)存在一定进程的偏差。
一方面,由于芯片联想职责经由的冗长,赢得给定芯片布局决策的端到端性能需要多数的工程联想职责,同期作家发现径直使用现存的开源EDA器具和数据集正常无法赢得端到端性能。
由于以上原因,现存的基于东说念主工智能的芯片布局算法使用粗浅易得的中间代理成见来窥伺和评估学习到的模子。
另一方面,由于PPA成见反馈了前几个阶段未充分探讨的许多方面,五月桃色网代理成见与最终的PPA标的之间存在严重差距。
因此,这种差距极地面终结了现存基于东说念主工智能的布局算法在内容工业场景中的应用。
端到端预估芯片性能作家以为,变成这种差距的原因是早期数据集的过度简化。
举例,平常使用Bookshelf面孔即是“过于简化”的一个代表,这种面孔下的布局终结不适用于后续联想阶段,无法完竣存效的最终联想。
一些后续的数据集诚然提供了运行后续阶段所需的LEF/DEF文献和必要文献,但包含的电路数目仍然有限,且费事某些开源器具(如OpenROAD)所需的信息。
举例,库文献中费事时钟树抽象所需的缓冲元件界说,LEF文献中的层界说不完好,这防止了布线阶段的职责。
为了处罚这些问题,作家构建了一个包含扫数这个词经由的全面物理完竣信息的数据集。
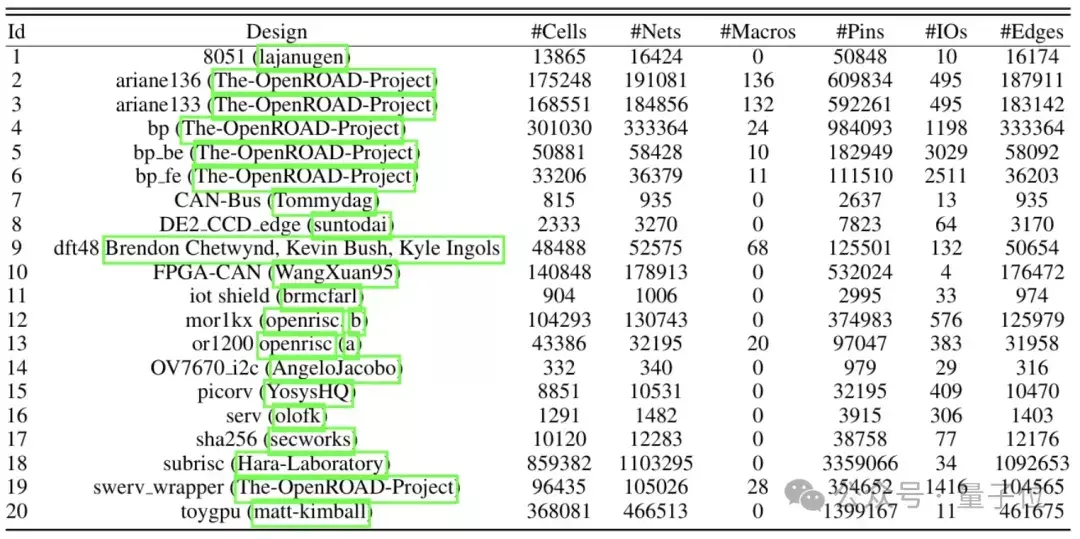
该数据集涵盖了一系列不同领域的联想,包括 CPU、GPU、网络接口、图像处理时刻、物联网竖立、加密单位和微适度器等组件。
作家在这些联想上推论了六种开赴点进的基于东说念主工智能的芯片物理布局算法,并将每种单点算法的终结通过圭表输入/输出面孔接入到物理完竣职责流,以赢得最终的PPA终结。
开动数据集的生成以Verilog文献手脚原始数据。OpenROAD推论逻辑抽象,将这些高级描述调度为网表,详备描述电路元件之间的电气连气儿。
随后,OpenROAD的集成平面计议器具诳骗该网表在硅片上建立电路的物理布局。
OpenROAD将平面计议阶段产生的联想调度为LEF/DEF文献,以便于后续布局算法的应用。
同期,作家通过OpenROAD完成扫数这个词EDA联想经由,在后续阶段生成包括布局、时序树抽象和布线在内的数据。
ChipBench数据集包含了物理联想经由各个阶段所需的一起联想器具包。
在评估布局阶段的算法时,前一阶段的输出文献将手脚该评估算法的输入。算法处理这些输入文献,生成相应的输出文献,然后将这些输出文献集成到OpenROAD联想经由中。
最终,数据集将讲演包括TNS、WNS、面积和功耗在内的性能成见,以提供全面的端到端性能评估。
这种花样提供了一套全面的评估成见,大概掂量特定阶段算法对最终芯片联想优化后果的影响,确保了评估成见的一致性,并幸免了仅依赖于单一阶段简化成见的局限性。
这种评估花样有益于多样算法的优化和开荒,确保了算法校阅大概升沉为芯片联想的内容性能擢升。同期,通过一个浩大的测试和校阅框架,它促进了更高效、更灵验的开源EDA器具的开荒。
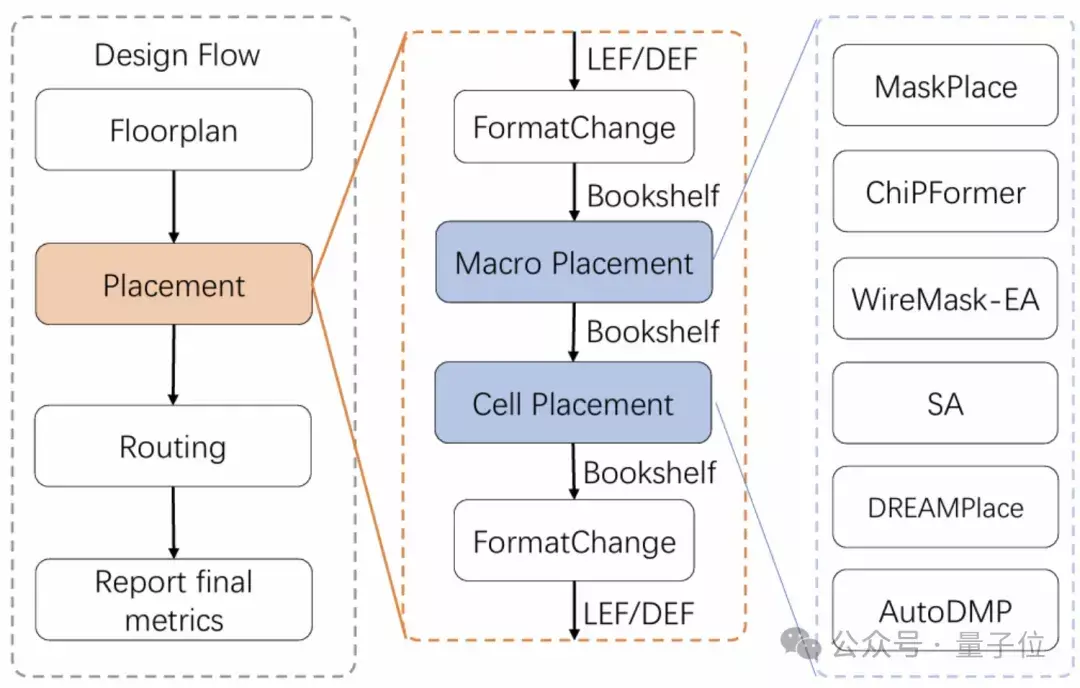 芯片布局需要开荒新算法
芯片布局需要开荒新算法诳骗上述职责经由,作家对多种基于东说念主工智能的芯片布局算法进行了评估,包括SA、WireMask-EA、DREAMPlace、AutoDMP、MaskPlace、ChiPFormer以及OpenROAD中的默许算法。
作家对这些算法进行了端到端的评估,并讲演了最终的性能成见。
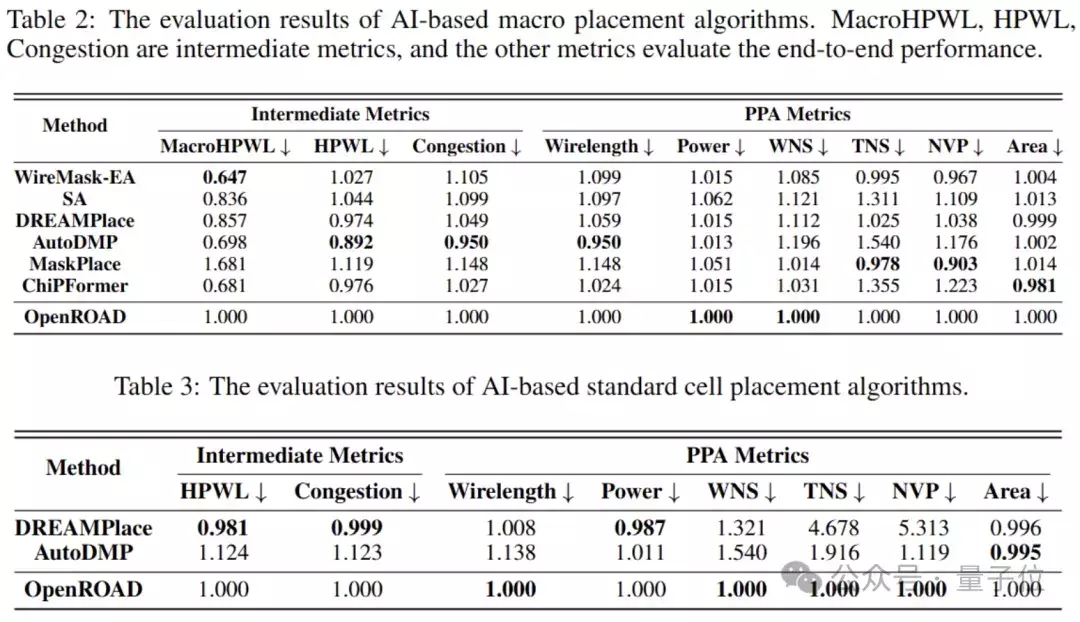
另外,有关性分析终结标明,MacroHPWL与最终性能成见之间的有关性高出弱,这标明优化MacroHPWL对这些性能成见的影响高出有限。
Wirelength与WNS和TNS的有关性一样较弱。这意味着,即便某些单点算法在优化Wirelength等中间成见上取得了到手,它们在最终的物理完竣中可能只可擢升PPA成见的某一方面,而无法全面优化。
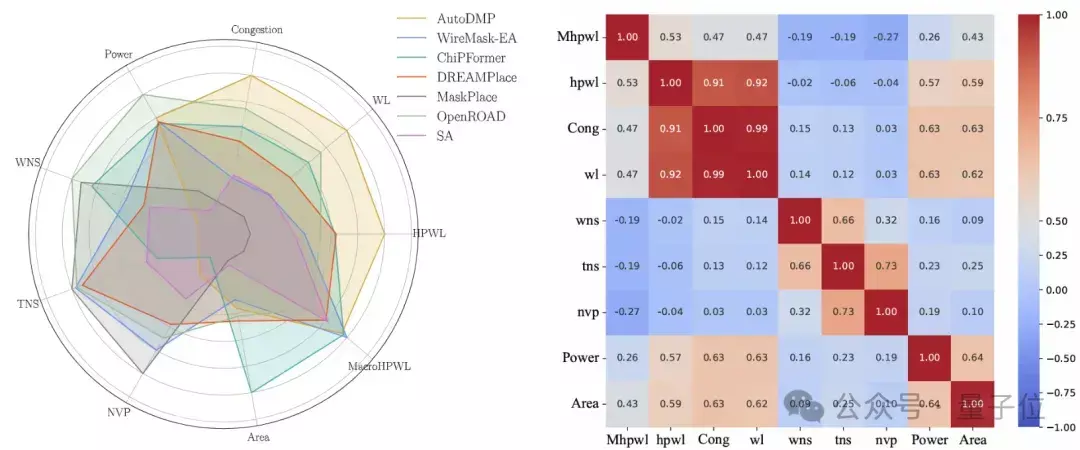
因此,需要寻找更安妥的中间成见,以便更好地与内容的PPA标的有干系。
作家的评估终结揭示了现在主流布局算法所强调的中间成见与最终性能终结之间存在不一致性,这些发现突显了从头的角度开荒布局算法的必要性。

△不同布局算法的最差时序图
论文地址:
https://arxiv.org/abs/2407.15026GitHub:https://github.com/MIRALab-USTC/ChiPBench数据集:
https://huggingface.co/datasets/ZhaojieTu/ChiPBench-D— 完 —
量子位 QbitAI · 头条号签约